Chatterbox TTS — 声音克隆
本教程为社区贡献,不属于 Open WebUI 官方支持内容。它仅作为如何针对特定用例定制 Open WebUI 的演示。想要参与贡献?请查看贡献教程。
什么是 Chatterbox TTS API?
Chatterbox TTS API 是一个 API 封装器,可用于声音克隆和文本转语音 (TTS),可以直接替代 OpenAI Speech API 端点。
![]()
核心特性
- 零样本 (Zero-shot) 声音克隆 — 仅需约 10 秒的任意语音样本
- 性能超越 ElevenLabs
- 输出带水印以保证声音克隆的负责任使用
- 基于 0.5B Llama 基底
- 自定义声音库管理
- 支持流式传输 (Streaming) 以实现极速生成
- 先进的内存/显存管理与自动清理
- 提供可选的前端界面以实现轻松管理和使用
硬件推荐
- 内存:最低 4GB,推荐 8GB+
- GPU:CUDA (Nvidia)、Apple M 系列 (MPS)
- CPU:可用但速度较慢 — 生产环境推荐使用 GPU
Chatterbox 会占用相当多的内存/显存,其硬件要求可能比您习惯的其他本地 TTS 解决方案要高。如果您的设备难以满足这些要求,您可能会发现 OpenAI Edge TTS 或 Kokoro-FastAPI 是合适的替代品。
⚡️ 快速开始
🐍 使用 Python
选项 A:使用 uv(推荐 - 更快且依赖关系更佳)
# 克隆仓库
git clone https://github.com/travisvn/chatterbox-tts-api
cd chatterbox-tts-api
# 如果尚未安装 uv,请先安装
curl -LsSf https://astral.sh/uv/install.sh | sh
# 使用 uv 安装依赖(会自动创建 venv)
uv sync
# 复制并定制环境变量
cp .env.example .env
# 使用 FastAPI 启动 API
uv run uvicorn app.main:app --host 0.0.0.0 --port 4123
# 或者运行主脚本
uv run main.py💡 为什么选择 uv? 用户反馈其与
chatterbox-tts的兼容性更好,安装速度提升 25-40%,且依赖解析能力非常出色。查看迁移指南 →
选项 B:使用 pip(传统方式)
# 克隆仓库
git clone https://github.com/travisvn/chatterbox-tts-api
cd chatterbox-tts-api
# 设置环境 — 使用 Python 3.11
python -m venv .venv
source .venv/bin/activate
# 安装依赖
pip install -r requirements.txt
# 复制并定制环境变量
cp .env.example .env
# 添加您的声音样本(或使用提供的样本)
# cp your-voice.mp3 voice-sample.mp3
# 使用 FastAPI 启动 API
uvicorn app.main:app --host 0.0.0.0 --port 4123
# 或者运行主脚本
python main.py遇到问题了?请查看 故障排除章节
🐳 Docker(推荐)
# 克隆并使用 Docker Compose 启动
git clone https://github.com/travisvn/chatterbox-tts-api
cd chatterbox-tts-api
# 使用针对 Docker 优化的环境变量
cp .env.example.docker .env # 针对 Docker 的路径,开箱即用
# 或者使用本地开发路径(需要定制):cp .env.example .env
# 选择您的部署方法:
# 仅 API (默认)
docker compose -f docker/docker-compose.yml up -d # 标准 (基于 pip)
docker compose -f docker/docker-compose.uv.yml up -d # uv 优化版 (构建更快)
docker compose -f docker/docker-compose.gpu.yml up -d # 标准 + GPU
docker compose -f docker/docker-compose.uv.gpu.yml up -d # uv + GPU (GPU 用户推荐)
docker compose -f docker/docker-compose.cpu.yml up -d # 纯 CPU
# API + 前端 (在上述任何命令后加上 --profile frontend)
docker compose -f docker/docker-compose.yml --profile frontend up -d # 标准 + 前端
docker compose -f docker/docker-compose.gpu.yml --profile frontend up -d # GPU + 前端
docker compose -f docker/docker-compose.uv.gpu.yml --profile frontend up -d # uv + GPU + 前端
# 观察初始化时的日志(首次使用 TTS 时耗时最长)
docker logs chatterbox-tts-api -f
# 测试 API
curl -X POST http://localhost:4123/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{"input": "Hello from Chatterbox TTS!"}' \
--output test.wav🚀 运行前端界面
本项目包含一个可选的基于 React 的 Web UI。您可以使用 Docker Compose 的 profiles 轻松启用或禁用前端:
使用 Docker Compose Profiles
# 仅 API (默认行为)
docker compose -f docker/docker-compose.yml up -d
# API + 前端 + Web UI (使用 --profile frontend)
docker compose -f docker/docker-compose.yml --profile frontend up -d
# 或者使用全栈启动助手脚本:
python start.py fullstack
# 相同的模式适用于所有的部署变体:
docker compose -f docker/docker-compose.gpu.yml --profile frontend up -d # GPU + 前端
docker compose -f docker/docker-compose.uv.yml --profile frontend up -d # uv + 前端
docker compose -f docker/docker-compose.cpu.yml --profile frontend up -d # CPU + 前端本地开发
对于本地开发,您可以分开运行 API 和前端:
# 先启动 API (遵循前面的指南)
# 然后运行前端:
cd frontend && npm install && npm run devNote: 如果遇到依赖问题,可以尝试运行
npm install --force而不是单纯的npm install。
点击 Vite 提供的链接以访问 Web UI。
生产环境构建
构建前端以进行生产环境部署:
cd frontend && npm install && npm run buildNote: 如果因依赖冲突导致构建失败,可以尝试使用
npm install --force。
构建完成后,您可以直接从本地文件系统的 /dist/index.html 访问它。
端口配置
- 仅 API:可在
http://localhost:4123访问(直接访问 API) - 带有前端:Web UI 位于
http://localhost:4321,API 请求将通过代理进行路由
前端使用反向代理路由请求。因此,在配合 --profile frontend 运行时,Web 界面将在 http://localhost:4321 可用,而 API 则运行在代理后面。
设置 Open WebUI 以使用 Chatterbox TTS API
我们推荐在配置 Open WebUI 设置之前运行前端界面,这样您就可以提前上传您想要使用的声音音频文件。如果正常启动(参见上述�指南),您可以访问 http://localhost:4321 进入前端。
若要在 Open WebUI 中使用 Chatterbox TTS API,请按照以下步骤操作:
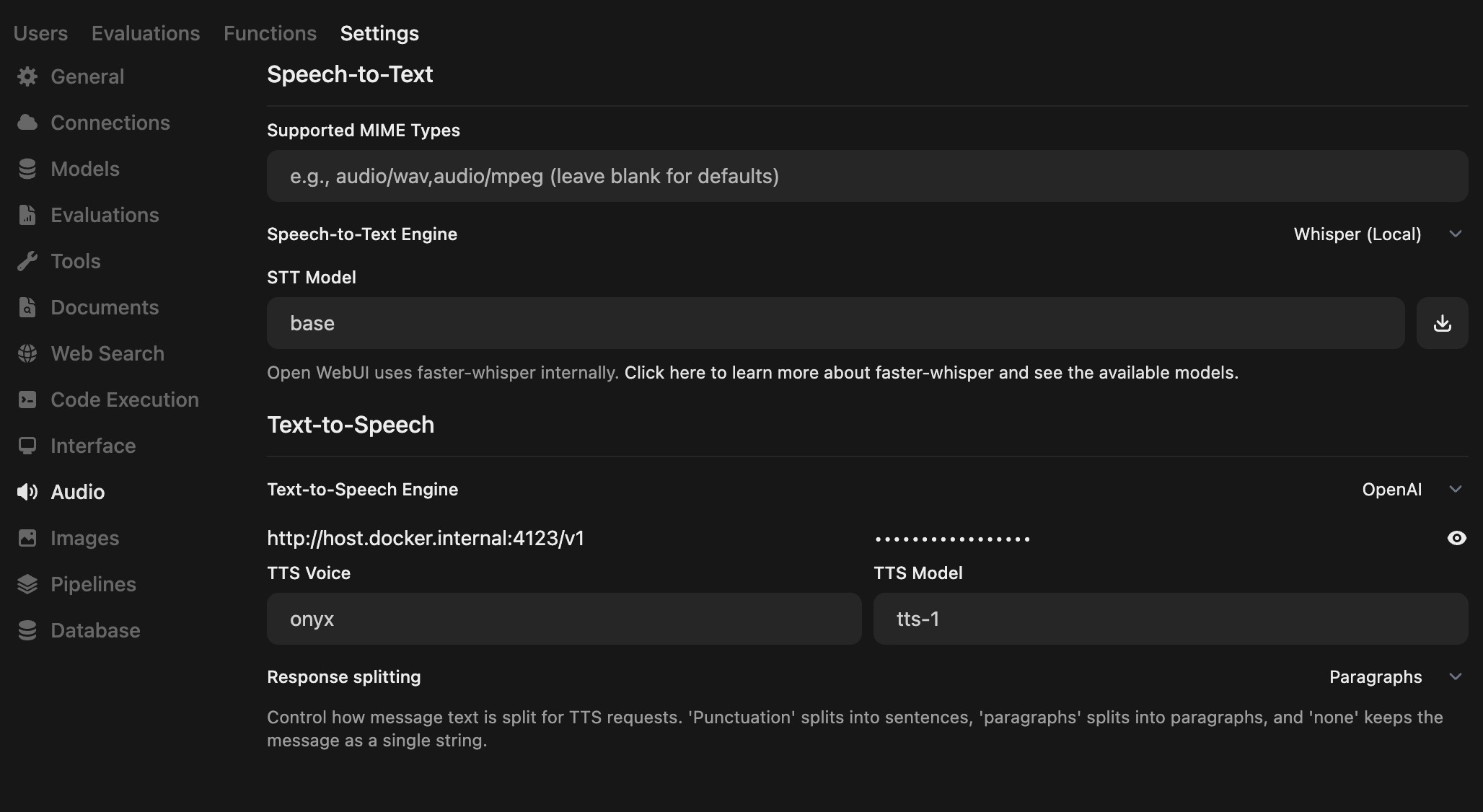
- 打开管理员面板 (Admin Panel),转到
设置->音频(Settings -> Audio) - 将您的 TTS 设置配置如下:
- 文本转语音引擎 (Text-to-Speech Engine):
OpenAI - API Base URL:
http://localhost:4123/v1# 或者尝试使用http://host.docker.internal:4123/v1 - API Key:
none - TTS 模型 (TTS Model):
tts-1或tts-1-hd - TTS 音色 (TTS Voice): 您已克隆的声音名称(也可以包括在前端定义的别名)
- 响应切分依据 (Response splitting):
Paragraphs(段落)
- 文本转语音引擎 (Text-to-Speech Engine):
默认的 API Key 为字符串 none(不需要实际的 API Key)
请在 GitHub ��上给 仓库加星 ⭐️ 以支持开发
需要帮助?
Chatterbox 在首次运行时可能会遇到一些挑战,如果某一种安装方式出现问题,您可以尝试其他的安装选项。
有关 chatterbox-tts-api 的更多信息,您可以访问 GitHub 仓库
- 📖 文档:参见 API 文档 和 Docker 指南
- 💬 Discord:加入本项目的 Discord 社区
故障排除
内存要求
相比于其他 TTS 解决方案,Chatterbox 具有更高的内存要求:
- 最低配置: 4GB RAM
- 推荐配置: 8GB+ RAM
- GPU: 推荐使用 NVIDIA CUDA 或 Apple M 系列 (MPS)
如果您遇到内存不足的问题,请考虑使用更轻量级的替代方案,如 OpenAI Edge TTS 或 Kokoro-FastAPI。
Docker 网络配置
如果 Open WebUI 无法连接到 Chatterbox:
- Docker Desktop:使用
http://host.docker.internal:4123/v1 - Docker Compose:使用
http://chatterbox-tts-api:4123/v1 - Linux:使用您主机的 IP 地址
首次启动
由于需要加载模型,第一次 TTS 请求会消耗明显更长的时间。您可以使用以下命令检查日志:
docker logs chatterbox-tts-api -f有关更多故障排除技巧,请参阅 音频故障排除指南。