本教程为社区贡献,不属于 Open WebUI 官方支持内容。它仅作为如何针对特定用例定制 Open WebUI 的演示。想要参与贡献?请查看贡献教程。
在 Open WebUI 中集成 openai-edge-tts 🗣️
什么是 openai-edge-tts?
OpenAI Edge TTS 是一个模拟 OpenAI API 端点规范的文本转语音 (TTS) API。因此,在允许定义端点 URL 的场景下(例如使用 Open WebUI),它可以直接作为替代方案。
它使用了 edge-tts Python 库,该库利用了 Edge 浏览器的免费“大声朗读 (Read Aloud)”功能,通过模拟对 Microsoft / Azure 的请求,来免费获取非常高质量的文本转语音音频。
它与 'openedai-speech' 有何不同?
与 openedai-speech 类似,openai-edge-tts 也是一个模拟 OpenAI API 端点规范的文本转语音 API,同样适用于 OpenAI Speech 端点可被调用且服务器端点 URL 可配置的场景下直接替代。
openedai-speech 是一个更为全面的选项,支持完全离线的语音生成,并拥有许多可选的生成模式。
openai-edge-tts 则更为简便,主要借助名为 edge-tts 的 Python 库来生成音频。
要求
- 系统中已安装 Docker
- Open WebUI 正在运行
⚡️ 快速开始
要在无需配置任何内容的情况下快速启动,最简单的方法是运行以下命令:
docker run -d -p 5050:5050 travisvn/openai-edge-tts:latest这将在 5050 端口上以所有默认配置启动该服务。
设置 Open WebUI 以使用 openai-edge-tts
- 打开管理员面板 (Admin Panel),转到
设置->音频(Settings -> Audio) - 按照下方的截图来配置您的 TTS 设置
- 注:您可以在此处指定默认的 TTS 音色 (TTS Voice)
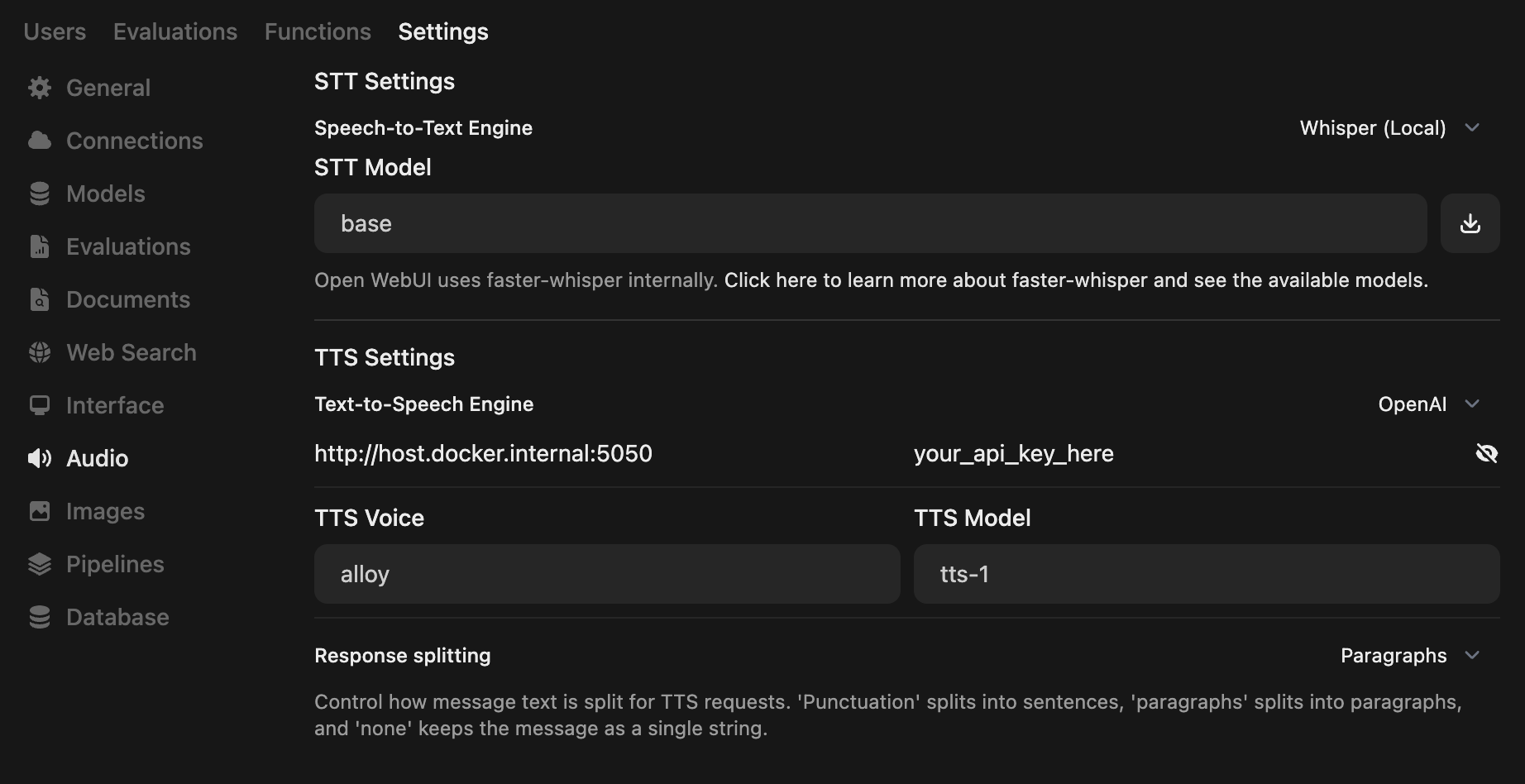
默认的 API Key 为字符串 your_api_key_here。如果您不需要额外的安全性,无需更改此值。
就这么简单!您可以到此结束了。
如果您觉得 OpenAI Edge TTS 有用,请在 GitHub 上给该仓库点亮星 ⭐️
使用 Python 运行
🐍 使用 Python 运行
如果您更倾向于直接使用 Python 运行此项目,请按照以下步骤配置虚拟环境、安装依赖并启动服务器。
1. 克隆仓库
git clone https://github.com/travisvn/openai-edge-tts.git
cd openai-edge-tts2. 设置虚拟环境
创建并激活虚拟环境以隔离项目依赖:
# 适用于 macOS/Linux
python3 -m venv venv
source venv/bin/activate
# 适用于 Windows
python -m venv venv
venv\Scripts\activate3. 安装依赖
使用 pip 安装 requirements.txt 中列出的所需包:
pip install -r requirements.txt4. 配置环境变量
在项目根目录下创建一个 .env 文件,并设置以下变量:
API_KEY=your_api_key_here
PORT=5050
DEFAULT_VOICE=en-US-AvaNeural
DEFAULT_RESPONSE_FORMAT=mp3
DEFAULT_SPEED=1.0
DEFAULT_LANGUAGE=en-US
REQUIRE_API_KEY=True
REMOVE_FILTER=False
EXPAND_API=True5. 运行服务器
配置完成后,使用以下命令启动服务器:
python app/server.py服务器将在 http://localhost:5050 上启动运行。
6. 测试 API
您现在可以在 http://localhost:5050/v1/audio/speech 和其他可用端点与 API 进行交互。请查看用法(Usage)部分以获取请求示例。
用法详情
端点:/v1/audio/speech (别名 /audio/speech)
将输入文本转换为音频。可用参数包括:
必填参数:
- input (string): 要转换为音频的文本(最多 4096 个字符)。
选填参数:
- model (string): 设置为 "tts-1" 或 "tts-1-hd" (默认:
"tts-1")。 - voice (string): 兼容 OpenAI 的音色之一(alloy, echo, fable, onyx, nova, shimmer)或任何有效的
edge-tts音色(默认:"en-US-AvaNeural")。 - response_format (string): 音频格式。选项:
mp3、opus、aac、flac、wav、pcm(默认:mp3)。 - speed (number): 播放速度(0.25 到 4.0)。默认是
1.0。
您可以在 tts.travisvn.com 浏览可用的音色并聆听示例试听。
使用 curl 请求并将输出保存为 mp3 文件的示例:
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{
"input": "Hello, I am your AI assistant! Just let me know how I can help bring your ideas to life.",
"voice": "echo",
"response_format": "mp3",
"speed": 1.0
}' \
--output speech.mp3或者,与 OpenAI API 端点参数完全一致的示例:
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{
"model": "tts-1",
"input": "Hello, I am your AI assistant! Just let me know how I can help bring your ideas to life.",
"voice": "alloy"
}' \
--output speech.mp3使用非英语语言(例如中文)的示例:
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{
"model": "tts-1",
"input": "你好,我是您的 AI 助手!有什么我可以帮您将创意变为现实的吗?",
"voice": "zh-CN-XiaoxiaoNeural"
}' \
--output speech.mp3其他端点
- POST/GET /v1/models: 列出可用的 TTS 模型。
- POST/GET /v1/voices: 列出给定语言/区域的
edge-tts音色。 - POST/GET /v1/voices/all: 列出所有的
edge-tts音色及对应的语言支持信息。
/v1 前缀现在是可选的。
此外,这里还包含了针对 Azure AI Speech 和 ElevenLabs 的端点,如果 Open WebUI 未来允许为这些服务配置自定义 API 端点,则可实现支持。
这些扩展端点可以通过设置环境变量 EXPAND_API=False 来禁用。
🐳 Docker 快速配置
您可以在运行项目的 Docker 命令中直接配置环境变量:
docker run -d -p 5050:5050 \
-e API_KEY=your_api_key_here \
-e PORT=5050 \
-e DEFAULT_VOICE=en-US-AvaNeural \
-e DEFAULT_RESPONSE_FORMAT=mp3 \
-e DEFAULT_SPEED=1.0 \
-e DEFAULT_LANGUAGE=en-US \
-e REQUIRE_API_KEY=True \
-e REMOVE_FILTER=False \
-e EXPAND_API=True \
travisvn/openai-edge-tts:latestMarkdown 文本现在已经过过滤器处理,以实现更佳的可读性和支持度。
您可以通过将环境变量设置为 REMOVE_FILTER=True 来禁用此过滤器。
额外资源
有关 openai-edge-tts 的更多信息,您可以访问 GitHub 仓库。
如需直接的技术支持,您可以加入 Voice AI & TTS Discord 频道。
🎙️ 音色样本
故障排除
连接问题
无法在 Docker 中访问 "localhost"
如果 Open WebUI 在 Docker 容器中运行,且无法访问位于 localhost:5050 的 TTS 服务:
解决方案:
- 使用
host.docker.internal:5050代替localhost:5050(适用于 Windows/Mac 上的 Docker Desktop)。 - 在 Linux 上,请使用主机的 IP 地址,或者在 Docker run 命令中添加
--network host参数。 - If 两个服务都在同一个 Docker Compose 中运行,请直接使用容器名称:
http://openai-edge-tts:5050/v1
在同一个 Docker 网络下运行这两个服务的 Docker Compose 示例:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
environment:
- AUDIO_TTS_ENGINE=openai
- AUDIO_TTS_OPENAI_API_BASE_URL=http://openai-edge-tts:5050/v1
- AUDIO_TTS_OPENAI_API_KEY=your_api_key_here
networks:
- webui-network
openai-edge-tts:
image: travisvn/openai-edge-tts:latest
ports:
- "5050:5050"
environment:
- API_KEY=your_api_key_here
networks:
- webui-network
networks:
webui-network:
driver: bridge测试 TTS 服务
验证 TTS 服务是否可独立正常工作�:
curl -X POST http://localhost:5050/v1/audio/speech \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your_api_key_here" \
-d '{"input": "Test message", "voice": "alloy"}' \
--output test.mp3如果此命令能成功生成音频,但 Open WebUI 仍然无法连接,说明问题出在容器间的网络连接上。
Open WebUI 中没有音频输出
- 检查您的 API Base URL 是否以
/v1结尾。 - 验证两个服务之间的 API Key 是否匹配(或者直接移除 Key 要求)。
- 检查 Open WebUI 容器日志:
docker logs open-webui。 - 检查 openai-edge-tts 容器日志:
docker logs openai-edge-tts(or 您指定的容器名称)。
有关更多故障排除技巧,请参阅 音频故障排除指南。