兼容 OpenAI
概述
Open WebUI 可以连接到任何实现了兼容 OpenAI 的 API 的服务器或提供商。本指南介绍了如何为流行的云端提供商和本地服务器设置连接。
对于 OpenAI 本身(或 Azure OpenAI),请参阅专门的 OpenAI 指南。
面向协议的设计
Open WebUI 是围绕标准协议构建的。我们没有为每个独立的 AI 提供商构建特定的模块(这会导致行为不一致和配置臃肿),而是专注于像 OpenAI Chat Completions 协议 这样的标准。
这意味着,虽然 Open WebUI 负责界面和工具,但它要求您的后端遵循通用的 Chat Completions 标准。
- 我们支持协议:任何遵循广泛采用的 API 标准的提供商都会得到原生支持。我们还对 Open Responses 提供了实验性支持。
- 我们避免专有 API:为了保持通用、可维护的代码库,我们不会在核心中实现特定于提供商的非标准 API。对于不支持的提供商,请使用管道(Pipe)或类似 LiteLLM 或 OpenRouter 的中间件代理来连接它们。
有关此架构决策的详细解释,请参阅我们的 关于协议支持的 FAQ。
当您添加连接时,Open WebUI 会通过使用标准的 Bearer Token 调用提供商的 /models 端点来验证连接。一些提供商根本没有实现 /models 端点,或者对其使用了非标准的身份验证。在这些情况下:
- 连接验证将失败并报错(例如 400、401 或 403)。
- 这并不意味着提供商不兼��容——对话补全(Chat completions)仍将正常工作。
- 您只需在连接设置中手动将模型名称添加到 模型 ID (过滤) 白名单中。
已知存在 /models 问题的提供商:
| 提供商 | /models 是否可用? | 需要采取的行动 |
|---|---|---|
| Anthropic | 是 — 内置兼容层 | 自动检测正常工作 |
| GitHub Models | 否 — 使用了非标准路径 | 手动将模型 ID 添加到白名单中 |
| Perplexity | 否 — 端点不存在 | 手动将模型 ID 添加到白名单中 |
| MiniMax | 否 — 端点不存在 | 手动将模型 ID 添加到白名单中 |
| OpenRouter | 是 — 但会返回数千个模型 | 强烈建议添加过滤白名单 |
| Google Gemini | 是 | 自动检测正常工作 |
| DeepSeek | 是 | 自动检测正常工作 |
| Mistral | 是 | 自动检测正常工作 |
| Groq | 是 | 自动检测正常工作 |
如何手动添加模型:在连接设置中,找到 模型 ID (过滤),键入模型 ID,点击 + 图标,然后保存。即使连接验证显示错误,这些模型也将出现在您的模型选择器中。
步骤 1:添加您的提供商连接
- 在浏览器中打开 Open WebUI。
- 转到 ⚙️ 管理员设置 → 外部连接 → OpenAI。
- 点击 ➕ 添加连接。
- 填写您的提供商的 URL 和 API Key(参见下方的选项卡)。URL 字段会在您键入时自动推荐常见的提供商端点。
- 如果您的提供商不支持
/models自动检测,请将您的模型 ID 添加到 模型 ID (过滤) 白名单中。 - 点击 保存。
如果是在 Docker 中运行 Open WebUI,且您的模型服务器运行在宿主机上,请将 URL 中的 localhost 替换为 host.docker.internal。
每个连接都有一个开关,允许您启用或禁用它而无需删除连接。这对于临时停用某个提供商并保留其配置信息非常有用。
云端提供商
- Anthropic
- Google Gemini
- DeepSeek
- Mistral
- Groq
- Perplexity
- MiniMax
- OpenRouter
- Amazon Bedrock
- Azure OpenAI
- LiteLLM
有关完整的逐步操作演练,请参阅专门的 Anthropic (Claude) 指南。
Anthropic (Claude) 提供了一个兼容 OpenAI 的端点。Open WebUI 包含一个内置的兼容层,该兼容层会自动检测 Anthropic 的 URL 并处理模型发现——只需填入您的 API Key,模型就会被自动检测到。请注意,这主要用于测试和对比——如需在生产环境中使用完整的 Claude 功能(PDF 处理、引用、深度思考、Prompt 缓存),Anthropic 建议使用其原生 API。
| 设置项 | 值 |
|---|---|
| URL | https://api.anthropic.com/v1 |
| API Key | 您在 console.anthropic.com 获取的 Anthropic API Key |
| 模型 ID | 自动检测 — 留空或过滤到特定模型 |
Google Gemini 提供了一个兼容 OpenAI 的端点,可与 Open WebUI 很好地配合使用。
| 设置项 | 值 |
|---|---|
| URL | https://generativelanguage.googleapis.com/v1beta/openai |
| API Key | 您在 aistudio.google.com 获取的 Gemini API Key |
| 模型 ID | 自动检测 — 留空或过滤到特定模型 |
URL 必须完全是 https://generativelanguage.googleapis.com/v1beta/openai —— 末尾不要带斜杠。末尾带斜杠会导致 /models 端点调用失败。
DeepSeek 完全兼容 OpenAI,支持正常的 /models 自动检测。
| 设置项 | 值 |
|---|---|
| URL | https://api.deepseek.com/v1 |
| API Key | 您在 platform.deepseek.com 获取的 API Key |
| 模型 ID | 自动检测 (例如 deepseek-chat, deepseek-reasoner) |
Mistral AI 完全兼容 OpenAI,支持正常的 /models 自动检测。
| 设置项 | 值 |
|---|---|
| URL | https://api.mistral.ai/v1 |
| API Key | 您在 console.mistral.ai 获取的 API Key |
| 模型 ID | 自动检测 (例如 mistral-large-latest, codestral-latest, mistral-small-latest) |
Groq 通过兼容 OpenAI 的 API 提供极速推理。
| 设置项 | 值 |
|---|---|
| URL | https://api.groq.com/openai/v1 |
| API Key | 您在 console.groq.com 获取的 API Key |
| 模型 ID | 自动检测 (例如 llama-3.3-70b-versatile, deepseek-r1-distill-llama-70b) |
Perplexity 通过兼容 OpenAI 的对话补全端点提供搜索增强的 AI 模型。
| 设置项 | 值 |
|---|---|
| URL | https://api.perplexity.ai |
| API Key | 您在 perplexity.ai/settings(API 选项卡下)获取的 API Key |
| 模型 ID | 必需 — 手动添加 (例如 sonar-pro, sonar-reasoning-pro, sonar-deep-research) |
Perplexity 没有 /models 端点。您必须手动将模型 ID 添加到白名单中。此外,一些 Perplexity 模型可能会拒绝对诸如 stop 或 frequency_penalty 等特定参数的设置。
MiniMax 是一家领先的 AI 公司,提供高性能的、侧重于编码的模型。其最新的模型 MiniMax M2.5 专为编码、推理和多轮对话进行了优化。对于高频编程,其 Coding Plan 订阅方案比起标准的按 Token 计费具有更高的性价比。
| 设置项 | 值 |
|---|---|
| URL | https://api.minimax.io/v1 |
| API Key | 您的 Coding Plan API Key (参见下方的步骤 2) |
| 模型 ID | 必需 — 手动添加 (例如 MiniMax-M2.5) |
步骤 1:订阅 MiniMax Coding Plan
- 访问 MiniMax Coding Plan 订阅页面。
- 选择适合您需求的套餐(例如每月 10 美元的 Starter 套餐)。
- 完成订阅流程。
Starter 套餐每 5 小时提供 100 个 “Prompts”。一个 Prompt 大约相当于 15 次请求,相比传统的基于 Token 的计费,具有非常显著的性价比。详情请参见 MiniMax Coding Plan 官方文档。
步骤 2:获取您的 Coding Plan API Key
订阅成功后,您需要获取专门的 API Key。
- 导航至 账户/Coding Plan 页面。
- 点击 Reset & Copy 生成并复制您的 API Key。
- 安全地将此 Key 保存到密码管理器中。
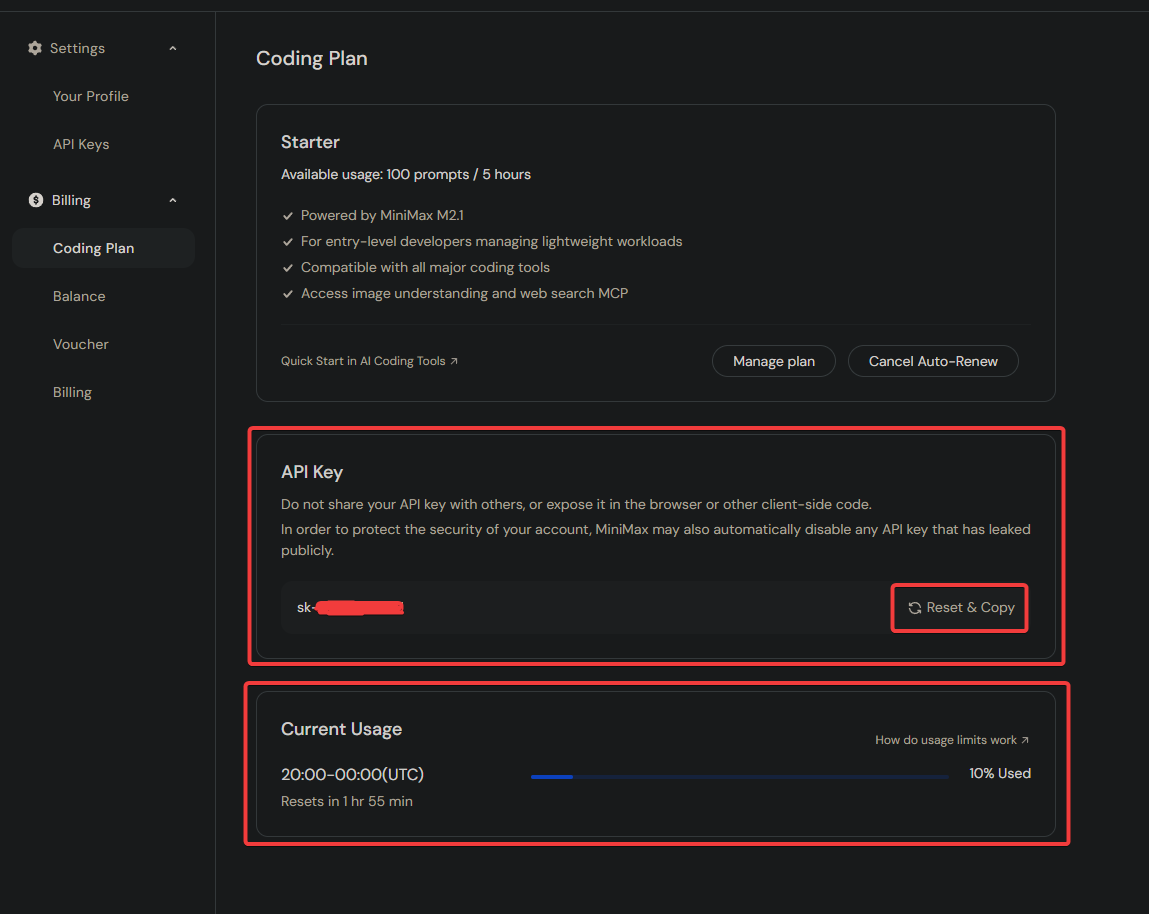
该 API Key 专属于 Coding Plan 套餐,与普通的按需付费(Pay-as-you-go)API Key 不能通用。
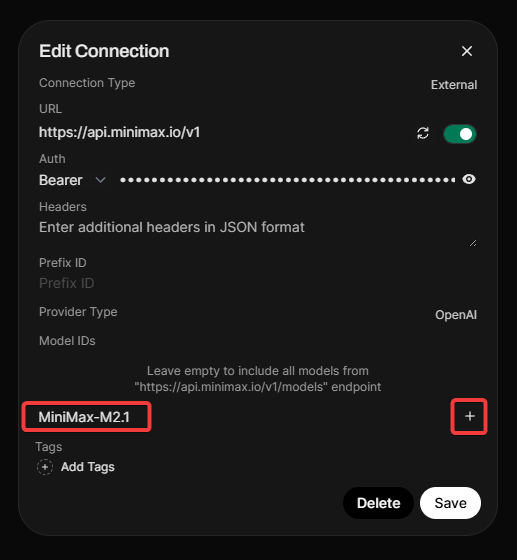
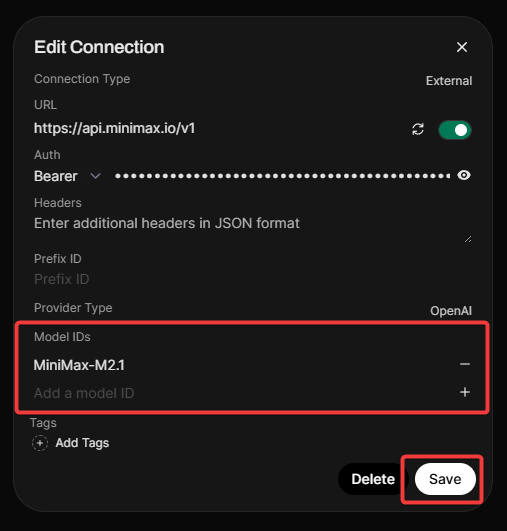
步骤 3:在 Open WebUI 中配置连接
- 打开 Open WebUI 并导航至 管理员�面板 > 设置 > 外部连接。
- 点击 OpenAI API 部分下的 +(加号)图标。
- 输入上表中的 URL 和 API Key。
- 重要提示:MiniMax 不公开
/models端点,因此您必须手动添加模型。 - 在 模型 ID (过滤) 中,输入
MiniMax-M2.5并点击 + 图标。 - 点击 验证连接 (您应该会看到成功提示)。
- 点击 保存。
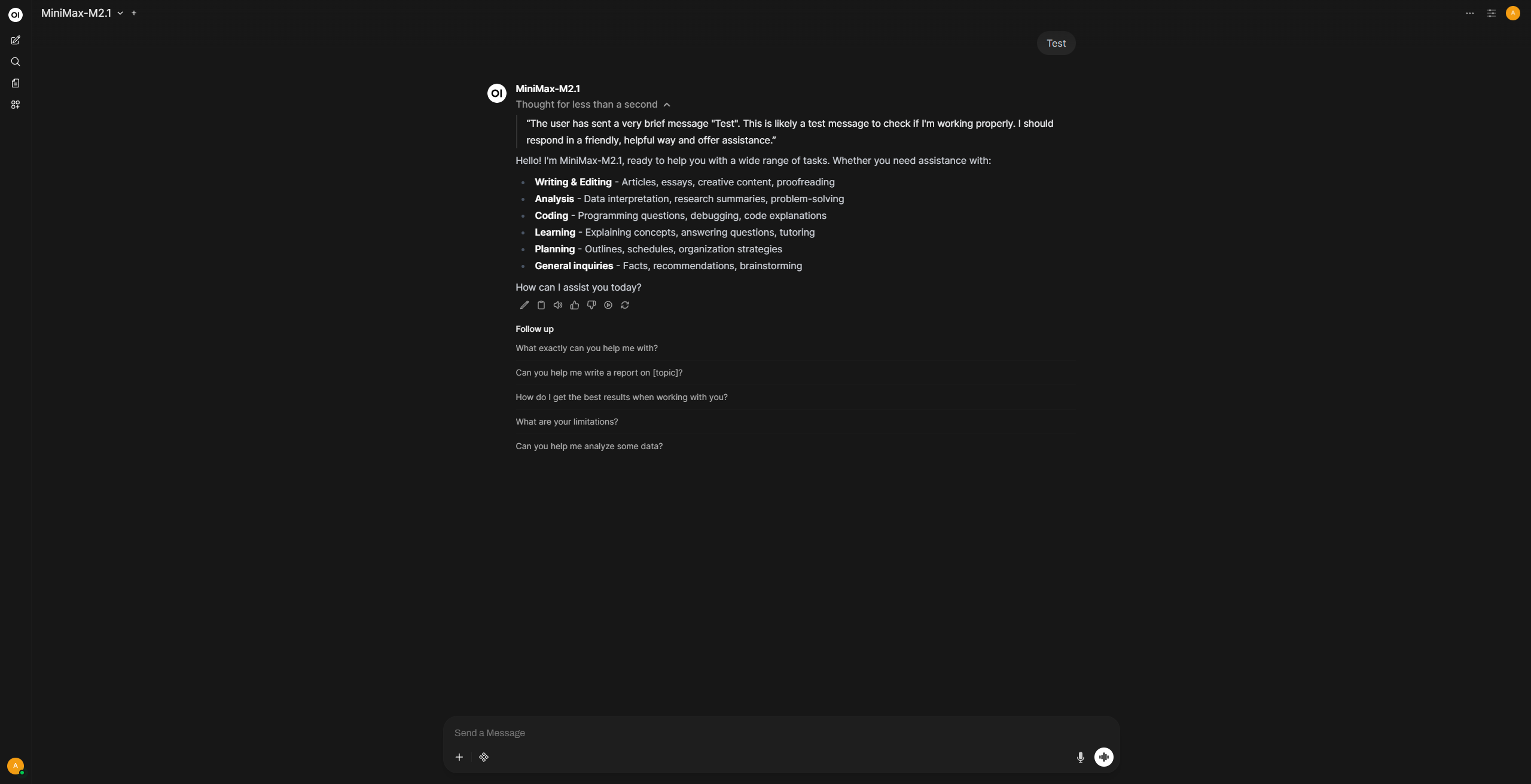
步骤 4:开始对话
从模型下拉菜单中选择 MiniMax-M2.5 并开始对话。推理和思考功能在默认情况下开箱即用,无需任何额外配置。
OpenRouter 通过单个 API 聚合了来自多个提供商的数百个模型。
| 设置项 | 值 |
|---|---|
| URL | https://openrouter.ai/api/v1 |
| API Key | 您在 openrouter.ai/keys 获取的 API Key |
| 模型 ID | 强烈建议 — 添加过滤白名单 |
OpenRouter 公开了数千个模型,这会堆满您的模型选择器并拖慢管理员面板。我们强烈建议:
- 使用白名单 — 仅添加您需要的特定模型 ID(例如
anthropic/claude-sonnet-4-5,google/gemini-2.5-pro)。 - 启用模型缓存 — 通过
设置 > 外部连接 > 缓存基础模型列表或ENABLE_BASE_MODELS_CACHE=True。如果不启用缓存,页面加载可能需要 10-15 秒以上。参见 性能指南 了解更多细节。
Amazon Bedrock 是一项完全托管的 AWS 服务,通过单个 API 提供了对来自领先 AI 公司(Anthropic, Meta, Mistral, Cohere, Stability AI, Amazon 等)的基础模型的访问。
有多种兼容 OpenAI 的方法可以将 Open WebUI 连接到 AWS Bedrock:
- Bedrock Access Gateway (BAG)
- stdapi.ai
- LiteLLM 及其 Bedrock 提�供商 (LiteLLM 并不专门针对 AWS)。
- Bedrock Mantle - AWS 原生方案,无需安装
功能对比
| 功能 | Bedrock Access Gateway (BAG) | stdapi.ai | LiteLLM (Bedrock 提供商) | AWS Bedrock Mantle |
|---|---|---|---|---|
| 模型自动发现 | ✅ | ✅ | — | ✅ |
| 对话补全 | ✅ | ✅ | ✅ | ✅ |
| 向量化模型 (Embeddings) | ✅ | ✅ | ✅ | — |
| 文本转语音 (TTS) | — | ✅ | — | — |
| 语音转文本 (STT) | — | ✅ | — | — |
| 图像生成 | — | ✅ | ✅ | — |
| 图像编辑 | — | ✅ | — | — |
| 来自多个区域的模型 | — | ✅ | ✅ | — |
| 无需安装 | — | — | — | ✅ |
| 授权协议 | MIT | AGPL 或商业授权 | MIT 或商业授权 | AWS 服务 |
方案 1:Bedrock Access Gateway (BAG)
前提条件
- 一个活跃的 AWS 账户
- 一个活跃的 AWS Access Key 和 Secret Key
- 启用 Bedrock 模型的 IAM 权限 (或者已启用模型)
- 系统上已安装 Docker
步骤 1:配置 Bedrock Access Gateway
BAG 是 AWS 开发的一个代理,它包装了原生的 Bedrock SDK 并公开了兼容 OpenAI 的端点。下面是端点映射表:
| OpenAI 端点 | Bedrock 方法 |
|---|---|
/models | list_inference_profiles |
/models/{model_id} | list_inference_profiles |
/chat/completions | converse 或 converse_stream |
/embeddings | invoke_model |
从 Bedrock Access Gateway GitHub 仓库 设置 BAG:
git clone https://github.com/aws-samples/bedrock-access-gateway
cd bedrock-access-gateway
# 使用 ECS Dockerfile
mv Dockerfile_ecs Dockerfile
docker build . -f Dockerfile -t bedrock-gateway
docker run -e AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID \
-e AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY \
-e AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN \
-e AWS_REGION=us-east-1 \
-d -p 8000:80 bedrock-gateway访问 http://localhost:8000/docs 上的 Swagger 页面来验证网关是否正常运行。
如果容器启动后立即退出(特别是在 Windows 上),请使用 docker logs <container_id> 检查日志。如果您看到 Python/Uvicorn 错误,这可能是 Python 3.13 兼容性问题。在构建前编辑 Dockerfile,将 python:3.13-slim 改为 python:3.12-slim,然后重新构建。
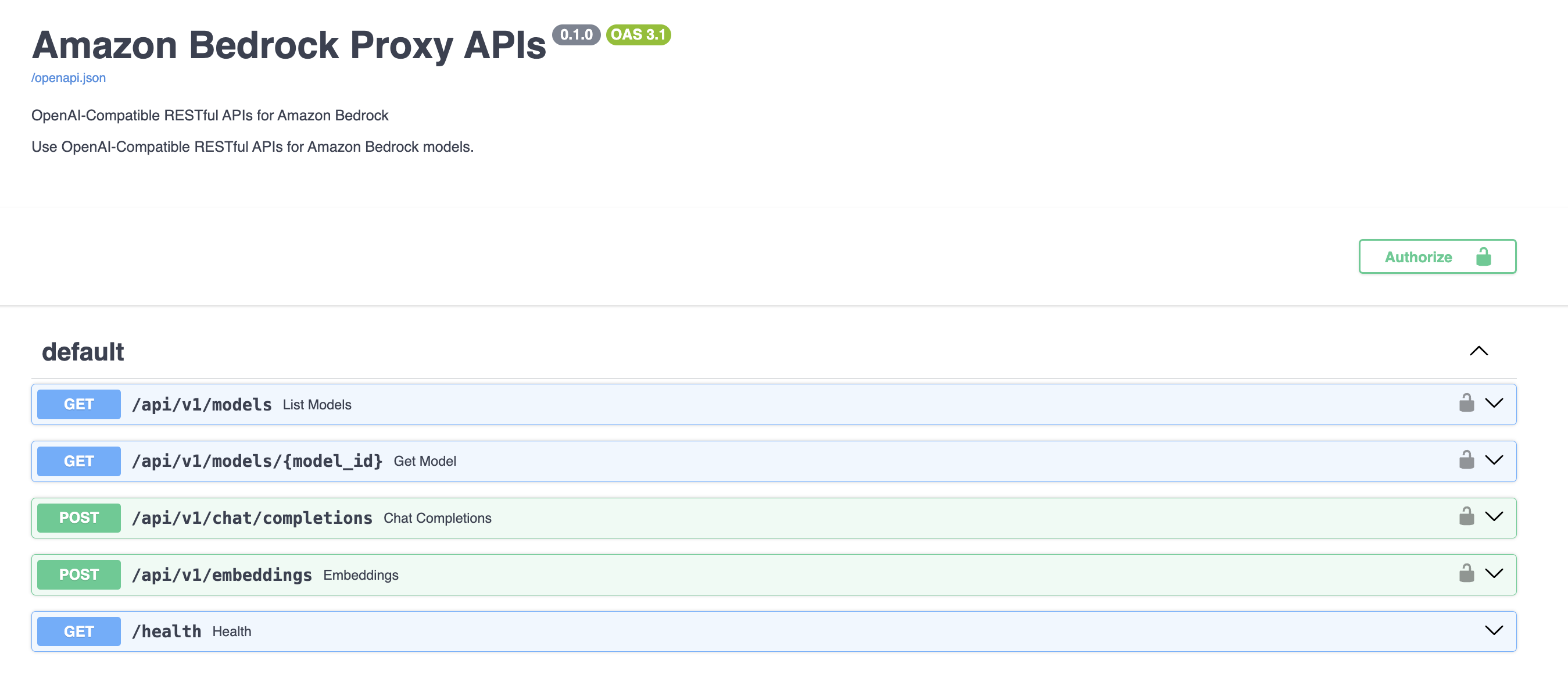
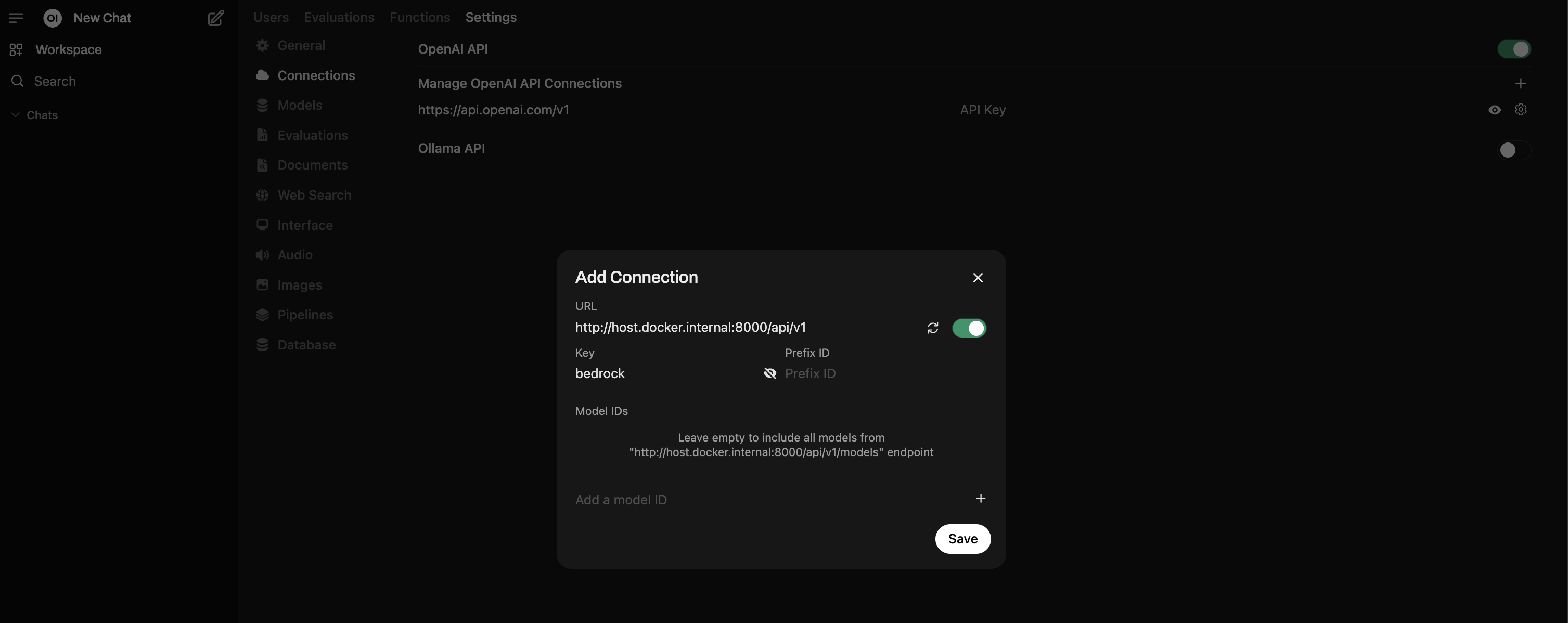
步骤 2:在 Open WebUI 中添加连接
- 在 管理员面板下,转到 设置 → 外部连接。
- 使用 OpenAI 下的 + 按钮添加新连接。
- 对于 URL,使用
http://host.docker.internal:8000/api/v1。 - 对于 API Key,BAG 中定义的默认 Key 是
bedrock(您可以通过 BAG 设置中的DEFAULT_API_KEYS来修改它)。 - 点击 验证连接 — 您应该会看到 “服务器连接已验证” 提示。
其他有用的教程
方案 2:stdapi.ai
stdapi.ai 是一个兼容 OpenAI 的 API 网关,您可以将其部署在您的 AWS 账户中,或者使用 Docker 本地运行。
Open WebUI 可以像连接 OpenAI 一样连接它,stdapi.ai 会将请求路由到 Bedrock 和其他 AWS AI 服务(例如 Amazon Polly 和 Transcribe)。它还支持对 Bedrock 的多区域访问,这使得您可以更容易地使用仅在特定 AWS 区域可用的模型。
在 AWS 上部署
stdapi.ai 提供了一个完整的 Terraform 示例,该示例在 ECS Fargate 上配置了 Open WebUI,将其连接到 stdapi.ai,并包含了配套服务,例如 Elasticache Valkey, Aurora PostgreSQL(带向量扩展), SearXNG 和 Playwright。 这种方法同时处理了 stdapi.ai 和 Open WebUI 的配置:
如果您希望将其连接到已有的 Open WebUI 实例,stdapi.ai 也提供了单独部署的文档和 Terraform 示例。
本地部署
stdapi.ai 也提供了一个用于本地使用的 Docker 镜像。
下面是使用您的 AWS 访问密钥运行它的最简命令:
docker run \
-e AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID \
-e AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY \
-e AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN \
-e AWS_BEDROCK_REGIONS=us-east-1,us-west-2 \
-e ENABLE_DOCS=true \
--rm \
-p 8000:8000 \
ghcr.io/stdapi-ai/stdapi.ai-community:latest该应用程序现已在 http://localhost:8000 上可用(在下面的 Open WebUI 配置中将其用作 YOUR_STDAPI_URL)。
AWS_BEDROCK_REGIONS 变量允许您选择要加载模型的区域,在本例中为 us-east-1 和 us-west-2。
如果您传递了 ENABLE_DOCS=true 变量,则可以在 http://localhost:8000/docs 访问交互式 Swagger 文档页面。
API_KEY=my_secret_password 也可用于为应用程序设置自定义 API Key(默认不需要 API Key)。如果可以从外部访问该服务器,强烈建议设置它。在下面的 Open WebUI 配置中将此 API Key 用作 YOUR_STDAPI_KEY。
还有许多其他配置选项可用,请参见官方文档了解更多信息。
Open WebUI 配置
Open WebUI 是通过环境变量配置的,您也可以在 Open WebUI 管理面板中设置相同的值。
为所有 *_OPENAI_API_KEY 条目使用相同的 stdapi.ai Key。
核心连接 (聊天 + 后台任务):
OPENAI_API_BASE_URL=YOUR_STDAPI_URL/v1
OPENAI_API_KEY=YOUR_STDAPI_KEY
# 为 `TASK_MODEL_EXTERNAL` 使用一个快速、低成本的对话模型。
TASK_MODEL_EXTERNAL=amazon.nova-micro-v1:0RAG 向量化模型 (Embeddings):
RAG_EMBEDDING_ENGINE=openai
RAG_OPENAI_API_BASE_URL=YOUR_STDAPI_URL/v1
RAG_OPENAI_API_KEY=YOUR_STDAPI_KEY
RAG_EMBEDDING_MODEL=cohere.embed-v4:0图像生成:
ENABLE_IMAGE_GENERATION=true
IMAGE_GENERATION_ENGINE=openai
IMAGES_OPENAI_API_BASE_URL=YOUR_STDAPI_URL/v1
IMAGES_OPENAI_API_KEY=YOUR_STDAPI_KEY
IMAGE_GENERATION_MODEL=stability.stable-image-core-v1:1图像编辑:
ENABLE_IMAGE_EDIT=true
IMAGE_EDIT_ENGINE=openai
IMAGES_EDIT_OPENAI_API_BASE_URL=YOUR_STDAPI_URL/v1
IMAGES_EDIT_OPENAI_API_KEY=YOUR_STDAPI_KEY
IMAGE_EDIT_MODEL=stability.stable-image-control-structure-v1:0语音转文本 (STT):
AUDIO_STT_ENGINE=openai
AUDIO_STT_OPENAI_API_BASE_URL=YOUR_STDAPI_URL/v1
AUDIO_STT_OPENAI_API_KEY=YOUR_STDAPI_KEY
AUDIO_STT_MODEL=amazon.transcribe文本转语音 (TTS):
AUDIO_TTS_ENGINE=openai
AUDIO_TTS_OPENAI_API_BASE_URL=YOUR_STDAPI_URL/v1
AUDIO_TTS_OPENAI_API_KEY=YOUR_STDAPI_KEY
AUDIO_TTS_MODEL=amazon.polly-neural如果您看到 TTS 语言的自动检测不一致,可以在 stdapi.ai 中设置固定语言(例如 DEFAULT_TTS_LANGUAGE=en-US)。
方案 3:AWS Bedrock Mantle
Bedrock Mantle 是一种 AWS 原生解决方案,为 Amazon Bedrock 提供了兼容 OpenAI 的 API 端点,无需任何额外的基础设施或安装。这使其成为了访问 Bedrock 模型的最简集成选项。
核心优势
- 无需安装 - 直接使用 AWS 托管端点
- 配置简单 - 仅需一个 API Key
- 原生 AWS 集成 - 由 AWS 完全托管
局限性
- 仅限对话补全 - 不支持向量化、图像生成或其他功能
- 仅限部分模型 - 仅提供对有限的 Bedrock 模型(开源权重模型)的访问
- 单一区域 - 不支持多区域访问
前提条件
- 一个活跃的 AWS 账户
- 一个 Amazon Bedrock API Key (在 AWS 控制台中创建一个)
- 使用 Bedrock 模型的 IAM 权限 (推荐使用
AmazonBedrockMantleInferenceAccessIAM 策略)
配置方法
使用环境变量配置 Open WebUI:
OPENAI_API_BASE_URL=https://bedrock-mantle.us-east-1.api.aws/v1
OPENAI_API_KEY=your_bedrock_api_key将 your_bedrock_api_key 替换为您创建的 Amazon Bedrock API Key。
将 URL 中的 us-east-1 替换为您偏好的 AWS 区域(例如 us-west-2、eu-west-1 等)。
您也可以在 Open WebUI 管理面板中设置相同的值。
有关更多信息,请参见 Bedrock Mantle 官方说明文档。
开始使用 Bedrock 基础模型
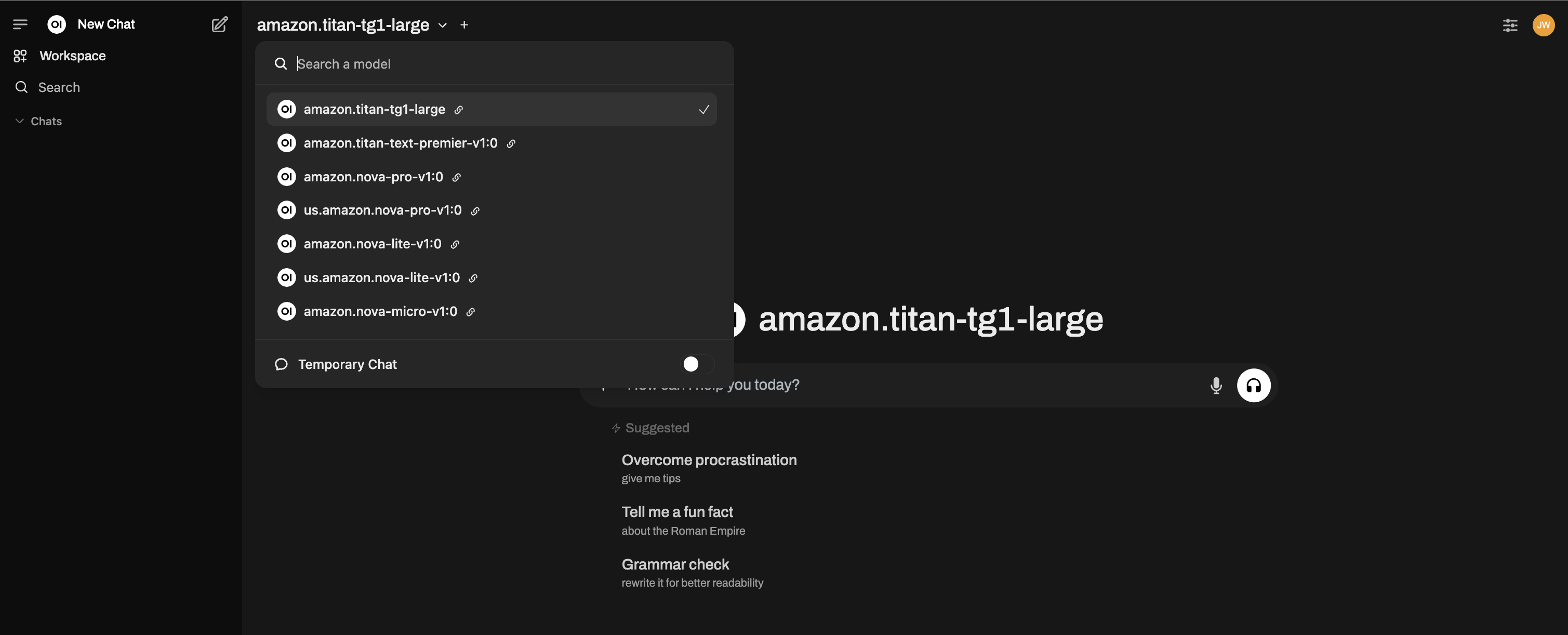
您现在应该会看到所有可用的 Bedrock 模型!
Azure OpenAI 通过 Microsoft Azure 提供企业级的 OpenAI 托管服务。
要添加 Azure OpenAI 连接,您需要在连接对话框中切换提供商类型:
- 在连接表单中,找到 提供商类型 (Provider Type) 按钮(默认显示为 OpenAI)。
- 点击该按钮将其切换为 Azure OpenAI。
- 填写以下设置。
| 设置项 | 值 |
|---|---|
| 提供商类型 | 点击切换为 Azure OpenAI |
| URL | 您的 Azure 端点 (例如 https://my-resource.openai.azure.com) |
| API 版本 | 例如 2024-02-15-preview |
| API Key | 您的 Azure API Key |
| 模型 ID | 必需 — 添加您具体的部署名称 (例如 my-gpt4-deployment) |
Azure OpenAI 使用**部署名称(Deployment Names)**作为模型 ID,而不是标准的 OpenAI 模型名称。您必须将您的部署名称添加到模型 ID 白名单中。
Azure 提供了两种 URL 格式:
- 旧版 (基于部署):
https://my-resource.openai.azure.com— Open WebUI 会将 URL 重写为/openai/deployments/{model}/...并自动添加api-version查询参数。 - v1 格式:
https://my-resource.openai.azure.com/openai/v1— 模型依然保留在请求体中(与标准 OpenAI 类似),且不需要api-version参数。
如果您的基础 URL 以 /openai/v1 结尾,Open WebUI 会跳过部署 URL 的重写,直接路由请求。使用您的 Azure 资源支持的任何一种格式即可。
有关使用 Azure Entra ID(RBAC、工作负载身份、托管身份)的免密钥高级身份验证,请参阅 使用 EntraID 的 Azure OpenAI 教程。
LiteLLM 是一个代理服务器,通过单个兼容 OpenAI 的 API 提供了对 100 多个 LLM 提供商(Anthropic, Google, Azure, AWS Bedrock, Cohere 等)的统一访问。它可以在提供商特定的 API 和 OpenAI 标准之间进行翻译。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:4000/v1 (默认的 LiteLLM 代理端口) |
| API Key | 您的 LiteLLM 代理密钥(如果配置了的话) |
| 模型 ID | 从您的 LiteLLM 配置中自动检测 |
快速配置:
pip install litellm
litellm --model gpt-4 --port 4000对于生产部署,可通过 litellm_config.yaml 配置模型。详情请参见 LiteLLM 官方文档。
当您想要使用的提供商不原生支持 OpenAI API 标准,或者您想要在多个提供商之间进行负载均衡时,LiteLLM 充当了一个非常实用的万能桥梁。
对于多用户部署,避免将提供商的管理/主(Master)Key 用于您的主 Open WebUI 连接。
倾向于使用最小特权的提供商凭证(在支持的情况下使用仅限推理权限的 Key)。这可以减少如果用户通过兼容 OpenAI 的集成调用了特定提供商端点时的潜在风险。
本地服务器
- Llama.cpp
- Lemonade
- LM Studio
- vLLM
- LocalAI
- Docker Model Runner
Llama.cpp 在本地运行高效、量化的 GGUF 模型,并提供了一个兼容 OpenAI 的 API 服务器。参见专门的 Llama.cpp 指南 获取完整的设置指南(包括安装、模型下载、服务器启动)。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:10000/v1 (或您配置的端口) |
| API Key | 留空 |
快速开始:
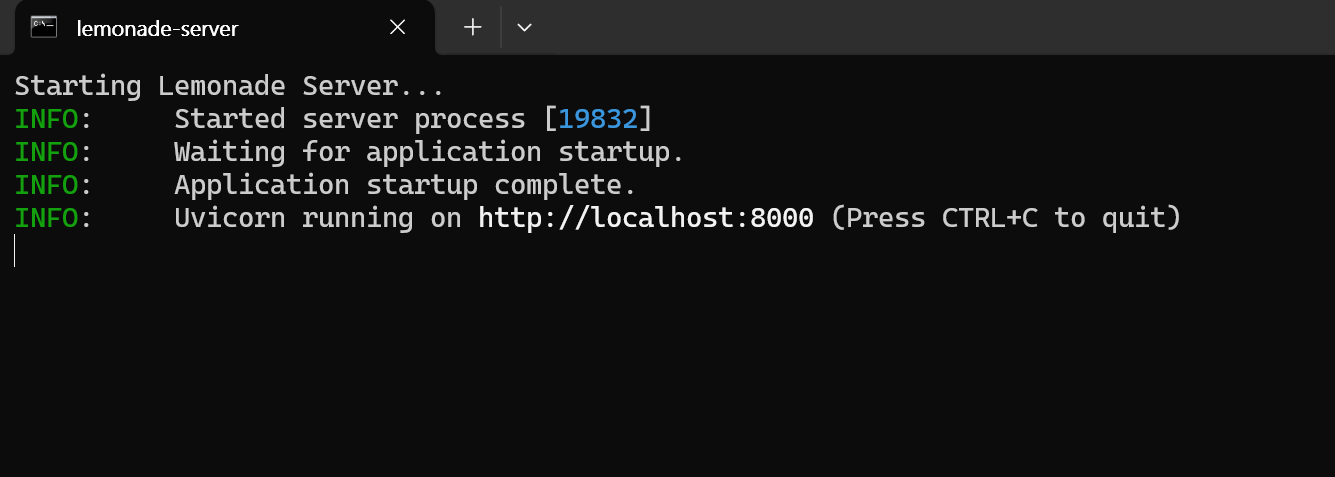
./llama-server --model /path/to/model.gguf --port 10000 --ctx-size 1024 --n-gpu-layers 40Lemonade 是一个适用于 Windows 的、开箱即用的、基于 ONNX 的兼容 OpenAI 的服务器。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:8000/api/v1 |
| API Key | 留空 |
开始使用 Lemonade:
- 下载最新的
.exe安装包。 - 运行
Lemonade_Server_Installer.exe。 - 使用 Lemonade 的安装器进行安装并下载模型。
- 启动后,您的 API 端点将为
http://localhost:8000/api/v1。
详情请见他们的文档。
然后,使用上面的 URL 和 API Key 在 Open WebUI 中添加连接:
LM Studio 提供了一个本地兼容 OpenAI 的服务器,并带有一个用于模型管理的图形界面。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:1234/v1 |
| API Key | 留空(或输入 lm-studio 作为占位符) |
连接前,在 LM Studio 中通过 “Local Server” 选项卡启动服务器。
vLLM 是一个高吞吐量的推理引擎,带有兼容 OpenAI 的服务器。有关完整的安装和配置说明,请参阅专门的 vLLM 指南。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:8000/v1 (默认的 vLLM 端口) |
| API Key | 留空 (除非进行了配置) |
LocalAI 是一个在本地运行模型并可直接替代 OpenAI 的方案。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:8080/v1 |
| API Key | 留空 |
Docker Model Runner 可以直接在 Docker 容器中运行 AI 模型。
| 设置项 | 值 |
|---|---|
| URL | http://localhost:12434/engines/llama.cpp/v1 |
| API Key | 留空 |
设置方法请参见 Docker Model Runner 说明文档。
如果您的服务器启动缓慢,或者您正在通过高延迟网络进行连接,可以调节模型列表获取的超时时间:
# 调整慢速连接的超时时间(默认是 10 秒)
AIOHTTP_CLIENT_TIMEOUT_MODEL_LIST=5如果您保存了一个无法访问的 URL 并导致 UI 变得无响应,请参阅 模型列表加载问题 故障排除指南以了解恢复选项。
必需的 API 端点
为了确保与 Open WebUI 的完全兼容,您的服务器应实现以下 OpenAI 标准端点:
| 端点 | 请求方法 | 是否必需? | 用途 |
|---|---|---|---|
/v1/models | GET | 推荐 | 用于模型发现并在 UI 中选择模型。如果不可用,请手动将模型添加到白名单中。 |
/v1/chat/completions | POST | 是 | 聊天对话的核心端点,支持流式传输和 Temperature 等参数。 |
/v1/embeddings | POST | 否 | 如果您希望将此提供商用于 RAG (检索增强生成) 则为必需。 |
/v1/audio/speech | POST | 否 | 文本转语音 (TTS) 功能所需。 |
/v1/audio/transcriptions | POST | 否 | 语音转文本 (STT/Whisper) 功能所需。 |
/v1/images/generations | POST | 否 | 图像生成 (DALL-E) 功能所需。 |
支持的参数
Open WebUI 会传递标准的 OpenAI 参数,例如 temperature、top_p、max_tokens(或 max_completion_tokens)、stop、seed 和 logit_bias。如果您的模型和服务器支持 tools 和 tool_choice 参数,它还支持工具调用 (Tool Use / Function Calling)。
步骤 2:开始对话!
在对话菜单中选择您已连接的提供商模型,然后开始对话!
大功告成!无论您选择的是云端提供商还是本地服务器,您都可以在 Open WebUI 中同时管理多个连接。
🚀 祝您构建完美 AI 配置的过程一切顺利!