Intel GPU (IPEX-LLM)
本教程由社区贡献,Open WebUI 团队不提供官方支持。它仅作为如何针对特定用例自定义 Open WebUI 的演示。想要贡献?请查看 贡献教程。
本指南已通过 手动安装 设置的 Open WebUI 进行验证。
在 Intel GPU 上使用 IPEX-LLM 设置本地 LLM
IPEX-LLM 是一个 PyTorch 库,用于在 Intel CPU 和 GPU(例如:配备集成显卡 iGPU 的本地个人电脑,��以及 Arc A-Series、Flex 和 Max 等独立显卡)上以极低的延迟运行 LLM。
本教程展示了如何使用由 IPEX-LLM 加速并托管在 Intel GPU 上的 Ollama 后端来配置 Open WebUI。通过遵循本指南,您甚至可以在低成本的个人电脑上(即仅包含集成显卡)设置 Open WebUI 并获得流畅的体验。
在 Intel GPU 上启动 Ollama 服务
有关如何在 Intel GPU 上安装和运行由 IPEX-LLM 加速的 Ollama 服务,请参阅 IPEX-LLM 官方文档中的此指南。
如果您想从另一台机器访问 Ollama 服务,请确保在执行 ollama serve 命令之前设置或导出环境变量 OLLAMA_HOST=0.0.0.0。
配置 Open WebUI
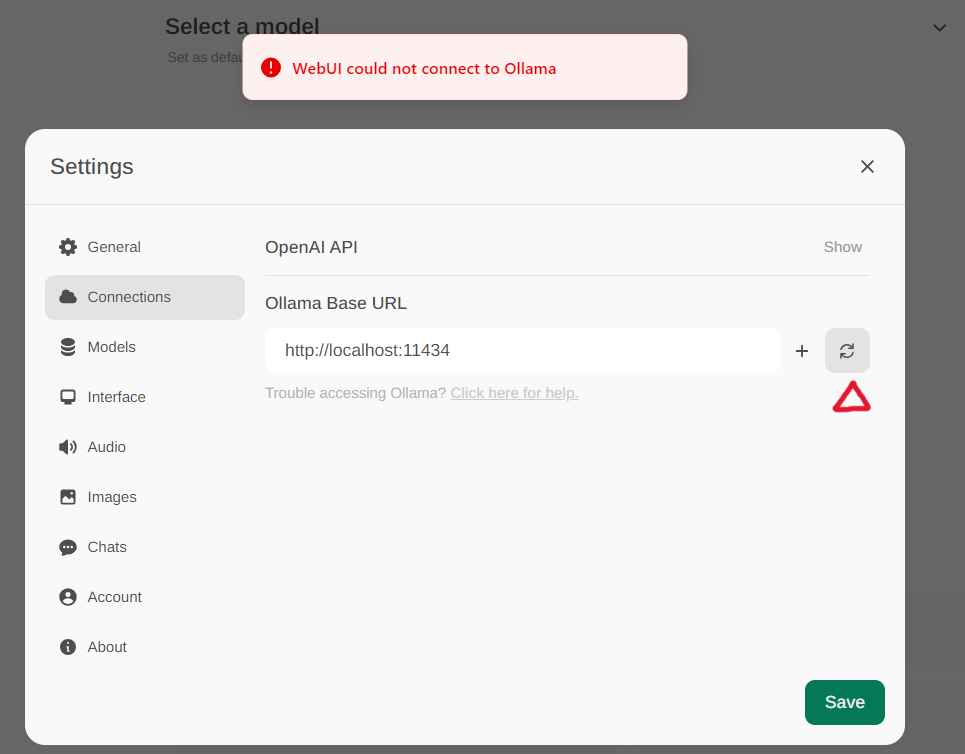
通过菜单中的 Settings(设置) -> Connections(连接) 访问 Ollama 设置。默认情况下,Ollama Base URL 预设为 https://localhost:11434,如以下截图所示。要验证 Ollama 服务的连接状态,请点击文本框旁边的刷新按钮。如果 WebUI 无法与 Ollama 服务器建立连接,您将看到一条错误消息,提示 WebUI could not connect to Ollama。
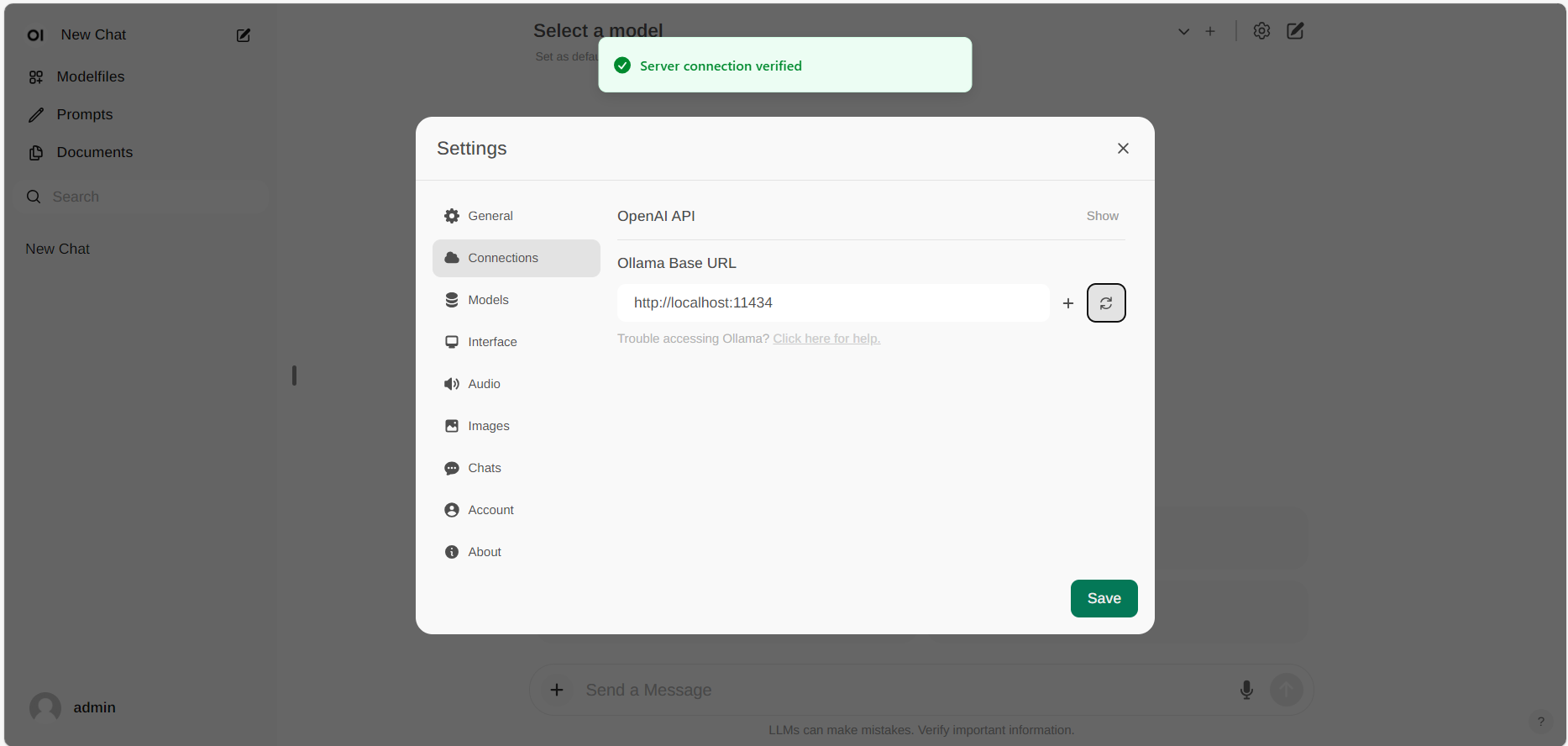
如果连接成功,您将看到一条消息,提示 Service Connection Verified,如下所示。
如果您想使用托管在不同 URL 上的 Ollama 服务器,只需将 Ollama Base URL 更新为新的 URL,然后按刷新按钮重新确认与 Ollama 的连接。